Métodos
Segementación interactiva
La segmentación es una técnica crucial en el procesamiento de imágenes y la visión por computadora, su objetivo puede ser la detección y extracción de uno o varios objetos específicos. Las características de los objetos, como el brillo, el color, la ubicación y el tamaño, pueden obtenerse automáticamente basándose en el conocimiento previo en un sistema de segmentación no supervisado o especificarse mediante la interacción del usuario en un sistema de segmentación interactiva 5.
Un sistema de segmentación interactiva consta de tres pasos que se repiten de forma iterativa hasta obtener el resultado deseado:
-
Entrada del Usuario: recibe las señales de entrada y/o control del usuario, lo que ayuda al sistema a reconocer la intención del usuario.
-
Algoritmo computacional: el algoritmo de segmentación se ejecuta automáticamente según la entrada del usuario y genera resultados de segmentación intermedios.
-
Visualización de Salida: muestra los resultados intermedios y final de la segmentación.
Un modelo clásico de imagen es tratar una imagen como un grafo. Se puede construir un grafo basado en las relaciones entre los píxeles, junto con el conocimiento previo de los objetos. El modelo de grafo más utilizado en la segmentación de imágenes es el campo aleatorio de Márkov (MRF)1, donde la segmentación de imágenes se formula como un problema de optimización que optimiza variables aleatorias, las cuales corresponden a etiquetas de segmentación, indexadas por nodos en el grafo de imagen.
La Figura 1 presenta un modelo de grafo para una imagen, dónde los píxeles marcados por el usuario para representar objetos y fondo son representados por los nodos terminales \(s\) (fuente) y \(t\) (sumidero), respectivamente, los pares seleccionados de nodos se conectan mediante aristas y se asigna un costo no negativo a cada arista; si una arista conecta un nodo no terminal con un nodo terminal, se llama t-link y si conecta dos nodos no terminales se llama n-link.
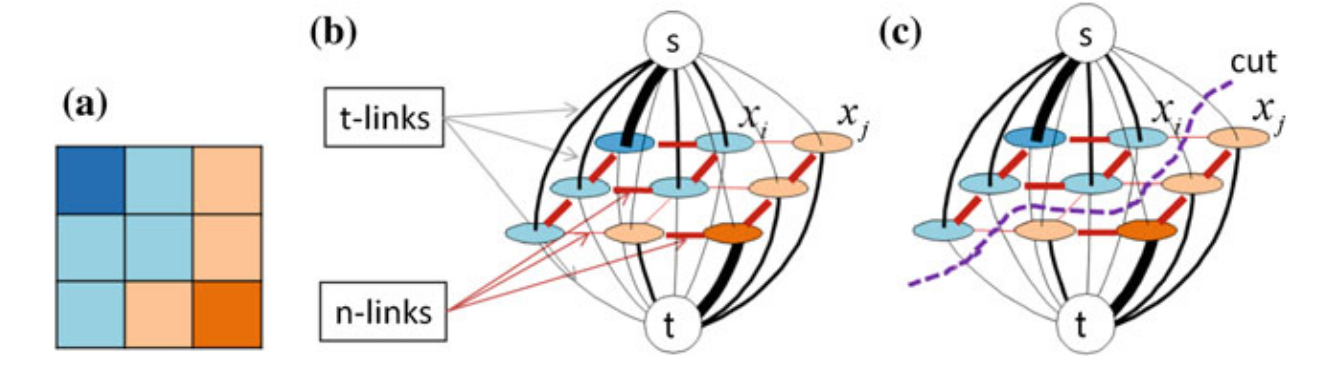
Graph-cut es un método de segmentación interactiva que se basa en cortes de grafos, donde el problema de segmentación se modela como un problema de estimación de máxima a posteriori (MAP) bajo el marco de MRF. Se resuelve utilizando un algoritmo rápido de min-cut/max-flow2 (flujo máximo/corte mínimo) para obtener una solución globalmente óptima.
En esta formulación del problema, una imagen se modela como un grafo (ver Figura 1), donde cada píxel representa un nodo y a cada arista se asigna un costo no negativo que refleja la probabilidad de que los píxeles conectados pertenezcan a la misma región (objeto o fondo). El objetivo es encontrar el corte en el grafo que minimice una función de costo, separando así los píxeles del objeto y del fondo, respetando las restricciones proporcionadas por las semillas, que son indicadas por el usuario. Las semillas generalmente corresponden al foreground (primer plano), indicando la región del objeto, y al background (fondo), indicando el fondo.
GrabCut
GrabCut es un algoritmo de segmentación de imágenes que permite separar un objeto del fondo de manera interactiva. Fue introducido por Rother et al. en su artículo "GrabCut: Interactive Foreground Extraction using Iterated Graph Cuts" 6 publicado en 2004, que utiliza el proceso de optimización de graph-cut en cada iteración. Este algoritmo tiene tres características principales según He et al. (2014) 5:
-
Modelo de Mezcla Gaussiana (GMM)3: GrabCut usa un GMM para representar los colores de los píxeles, en lugar del modelo de histograma monocromático utilizado en el algoritmo de graph-cut interactivo. El GMM permite una representación más precisa de la distribución de colores del objeto y del fondo. A partir del GMM se determinan los valores asignados de las aristas en función de la probabilidad de pertenencia al primer plano o al fondo.
-
Alternancia entre Estimación de Objeto y Estimación de Parámetros del GMM: En GrabCut, se alterna entre la estimación del objeto y la estimación de los parámetros del GMM de manera iterativa. Esto contrasta con el algoritmo de graph-cut interactivo, donde la optimización se realiza solo una vez. Este proceso iterativo mejora gradualmente la segmentación ajustando continuamente los parámetros del modelo. El proceso se repite hasta que la segmentación converja o se alcance un número máximo de iteraciones.
-
Menor Interacción del Usuario: GrabCut requiere menos interacción del usuario. Básicamente, el usuario solo tiene que colocar un rectángulo alrededor del objeto en lugar de dibujar trazos detallados. Los píxeles dentro del rectángulo se consideran una mezcla de primer plano y fondo, mientras que los píxeles fuera del rectángulo se consideran fondo.
Random Walker
El algoritmo Random Walker 7 (RW) también utiliza una representación de la imagen basada en grafos; se basa en un modelo donde un "caminante" comienza desde un nodo (pixel) marcado (interacción del usuario) y se mueve a sus nodos vecinos con una probabilidad específica, determinada por el peso de las aristas del grafo (ver Figura 1).
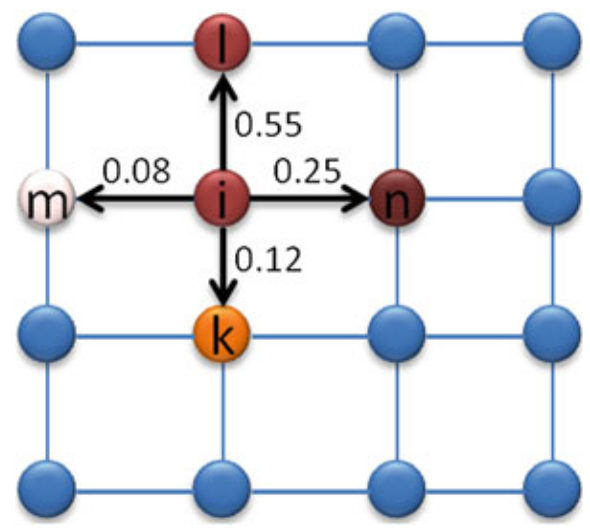
Los pesos de las aristas en el grafo se definen en función de las intensidades de los píxeles en la imagen original y se calculan utilizando una función exponencial para resaltar las diferencias en las intensidades de los píxeles. La fórmula general para calcular el peso de la arista que conecta dos píxeles \(i\) y \(j\) es (He et.al., 2014) 5:
donde:
- \(w(e_{ij})\) es el peso de la arista entre los píxeles \(i\) y \(j\).
- \(g_i\) y \(g_j\) son las intensidades de los píxeles \(i\) y \(j\) respectivamente.
- \(\beta\) es un parámetro de normalización que controla la sensibilidad del peso a las diferencias de intensidad.
Cuando la diferencia de intensidad \((g_i - g_j)^2\) es pequeña, el peso \(w(e_{ij})\) será grande, lo que indica que es más probable que el caminante aleatorio se mueva entre estos píxeles, y cuando la diferencia de intensidad es grande, el peso \(w(e_{ij})\) será pequeño, indicando una menor probabilidad de movimiento entre estos píxeles.
Se modela el problema como una cadena de Márkov, dónde el estado de cada nodo en un momento determinado solo depende del estado de sus nodos vecinos.
El algoritmo Random Walker puede resolverse como un problema de valores en la frontera de una ecuación diferencial parcial. En términos de grafos, esto se traduce en resolver un sistema lineal de ecuaciones. Los nodos marcados actúan como condiciones de frontera fijas y se utilizan para resolver las probabilidades de que cada píxel no marcado sea alcanzado primero por los píxeles de objeto o fondo. Finalmente cada píxel no marcado se etiqueta según la máxima probabilidad, completando la segmentación de la imagen.
Comparación de segmentaciones
Es importante evaluar y comparar la precisión de diferentes métodos de segmentación para determinar su efectividad. Para ello, se utilizan métricas específicas que cuantifican el grado de similitud entre una segmentación automática o interactiva y una segmentación de referencia (ground truth). A continuación, se presentan tres métricas comúnmente utilizadas en la evaluación de segmentaciones:
- Índice de Jaccard, también conocido como coeficiente de similitud de Jaccard o IoU (Intersection over Union), mide la similitud entre dos conjuntos. En el contexto de la segmentación de imágenes, se utiliza para medir la similitud entre dos máscaras binarias.
Donde:
- \(A\) es la máscara de referencia
- \(B\) es la máscara segmentada
- \(|A \cap B|\) es el número de píxeles en la intersección de A y B
- \(|A \cup B|\) es el número de píxeles en la unión de A y B.
Un valor cercano a 1 indica una alta similitud entre las máscaras (buena segmentación).
- Índice de Dice, también conocido como coeficiente de Dice o F1-score, mide la similitud entre dos conjuntos. Es similar al índice de Jaccard, pero tiene una fórmula ligeramente diferente que pone más énfasis en la intersección.
Donde:
- \(A\) es la máscara de referencia
- \(B\) es la máscara segmentada
- \(|A \cap B|\) es el número de píxeles en la intersección de A y B
- \(|A|+|B|\) es el número de total píxeles en ambas máscaras.
Un valor cercano a 1 indica una alta similitud entre las máscaras (buena segmentación).
- Error Adaptado de Rand (ARE)4 es una métrica utilizada para evaluar la precisión de la segmentación en imágenes, comparando una segmentación obtenida automáticamente (en este caso mediante técnicas interactivas) con una segmentación de referencia (ground_truth).
Se calcula como:
donde
- \(p_{ij}\) es la probabilidad de que un píxel tenga la misma etiqueta en la imagen de prueba y en la imagen verdadera
- \(t_k\) es la probabilidad de que un píxel tenga la etiqueta \(k\) en la imagen verdadera
- \(s_k\) es la probabilidad de que un píxel tenga la etiqueta \(k\) en la imagen de prueba.
El comportamiento predeterminado es ponderar la precisión y el recall por igual en el cálculo (\(\alpha = 0.5\)). Cuando \(\alpha = 0\), \(ARE = recall\) y cuando \(\alpha = 1\), \(ARE = precision\).
Un valor de ARE más bajo indica una mayor similitud entre las segmentaciones.
Implementación en python
La función grabcut permite segmentar objetos de interés en una imagen utilizando el algoritmo de GrabCut proporcionado por openCV.
Parámetros:
img: Imagen de entrada en formato de matriz NumPy, que debe estar en color (BGR).num_iter: Número de iteraciones que el algoritmo GrabCut deberá ejecutar para refinar la segmentación.
Proceso:
-
Selección de ROI: La función inicia mostrando la imagen y permitiendo al usuario seleccionar un rectángulo de interés (ROI) que incluya aproximadamente el objeto a segmentar, en este caso las palas. Esta selección se realiza con
cv2.selectROI. -
Inicialización de la Máscara y Modelos:
- Se crea una máscara inicial donde:
0: Fondo probable.1: Primer plano probable.2: Fondo seguro.3: Primer plano seguro.
-
Se inicializan dos matrices (
bgdModelyfgdModel) que el algoritmo utiliza internamente para representar los modelos de fondo y primer plano. -
Aplicación de GrabCut:
-
El algoritmo se ejecuta utilizando la función
cv2.grabCutcon el rectángulo seleccionado y las iteraciones especificadas. -
Creación de la Máscara Final:
-
Se transforma la máscara para que solo contenga valores binarios, donde
1representa el primer plano (objeto) y0el fondo. -
Aplicación de la Máscara a la Imagen:
- La máscara final se aplica a la imagen original para extraer el objeto segmentado.
- La función devuelve dos elementos:
img_result: La imagen resultante después de aplicar la máscara, mostrando solo el objeto segmentado.mask2: La máscara binaria final que indica la ubicación del objeto en la imagen.
def grabcut(img, num_iter=5):
# Mostrar la imagen y permitir al usuario seleccionar el rectángulo
rect = cv2.selectROI("Imagen", img, fromCenter=False, showCrosshair=True)
cv2.destroyWindow("Imagen")
# Crear una máscara inicial para el algoritmo
# (0: fondo probable, 1: primer plano probable, 2: fondo seguro, 3: primer plano seguro)
mask = np.zeros(img.shape[:2], np.uint8)
# Modelos de fondo y primer plano - internos de OpenCV
bgdModel = np.zeros((1, 65), np.float64)
fgdModel = np.zeros((1, 65), np.float64)
# Aplicar el algoritmo GrabCut
cv2.grabCut(img, mask, rect, bgdModel, fgdModel, num_iter, cv2.GC_INIT_WITH_RECT)
# Crear la máscara final donde 0 y 2 se convierten en fondo, y 1 y 3 en primer plano
mask2 = np.where((mask == 2) | (mask == 0), 0, 1).astype('uint8')
# Aplicar la máscara a la imagen original
img_result = img * mask2[:, :, np.newaxis]
return img_result, mask2
La función randomWalker se encarga de cargar una imagen, permitir la selección interactiva de puntos de semillas para el objeto y el fondo, y realizar la segmentación utilizando el algoritmo de Random Walker de scikit-image.
-
Selección de Puntos de Semillas
La función
select_pointspermite manejar los eventos del mouse para seleccionar puntos de semillas interactivos. Los puntos seleccionados se clasifican en dos categorías: objeto (clase 1) y fondo (clase 2). Se utilizacv2.setMouseCallbackdeOpenCV. -
Carga de Imagen y selección de semilla
Se carga la imagen en escala de grises para la segmentación. Se inicializan variables globales y una matriz de
markerspara almacenar las etiquetas de las semillas.Se abre una ventana donde el usuario puede seleccionar puntos de semillas para el objeto y el fondo. El usuario puede cambiar entre las clases de semillas presionando '1' y '2' en el teclado. El ciclo se ejecuta hasta que el usuario presiona 'ESC' para salir.
-
Segmentación con Random Walker
Los puntos seleccionados se utilizan para crear una matriz de markers, donde los píxeles etiquetados como objeto se marcan con 1 y los píxeles etiquetados como fondo se marcan con 2. Se utiliza la función
random_walkerdeskimage.segmentationpara segmentar la imagen en base a los markers.- Principales parámetros:
data: imagen a segmentarlabels: matriz de markers (semillas)beta: coeficiente de penalización para el movimiento del caminante aleatorio. Cuanto mayor sea beta, más difícil será la difusión.mode: método para resolver el sistema lineal en el algoritmo.bf: Fuerza bruta, rápida para imágenes pequeñas pero lenta y consume mucha memoria para imágenes grandes.cg: Gradiente conjugado, menos intensivo en memoria pero más lento.cg_j: Gradiente conjugado con preacondicionador Jacobi, acelera la convergencia del métodocg.cg_mg: Gradiente conjugado con preacondicionador multigrid, requiere el módulopyamg.
return_full_prob: si es True, se devuelve la probabilidad de que un píxel pertenezca a cada una de las etiquetas. Si es False devuelve la etiqueta más probable. Por defectoFalse- Salida
output: devuelve un array de enteros con la misma forma y tipo de datos que labels, donde cada píxel ha sido etiquetado según la primera etiqueta que alcanzó el píxel por difusión anisotrópica.
- Principales parámetros:
-
Aplicación de la Máscara y Guardado de Resultados Se crea una máscara binaria a partir de la segmentación y se aplica a la imagen original. La máscara y la imagen segmentada se guardan en el directorio de salida especificado.
def randomWalker(image_path, output_dir, beta=10, mode='bf'):
# función para seleccionar puntos para random walker
def select_points(event, x, y, flags, param):
global ix, iy, drawing, current_class, points_class1, points_class2
if event == cv2.EVENT_LBUTTONDOWN: # Botón izquierdo del mouse presionado
drawing = True
ix, iy = x, y # Almacenar coordenadas iniciales
elif event == cv2.EVENT_MOUSEMOVE: # Movimiento del mouse
if drawing:
if current_class == 1:
points_class1.append((x, y))
cv2.circle(img, (x, y), 1, (0, 0, 255), -1) # Rojo para clase 1
elif current_class == 2:
points_class2.append((x, y))
cv2.circle(img, (x, y), 1, (255, 0, 0), -1) # Azul para clase 2
cv2.imshow("Seleccionar puntos", img)
elif event == cv2.EVENT_LBUTTONUP: # Botón izquierdo del mouse no presionado
drawing = False
if current_class == 1:
points_class1.append((x, y))
cv2.circle(img, (x, y), 1, (0, 0, 255), -1) # Rojo para clase 1
elif current_class == 2:
points_class2.append((x, y))
cv2.circle(img, (x, y), 1, (255, 0, 0), -1) # Azul para clase 2
cv2.imshow("Seleccionar puntos", img)
# Carga la imagen
image = cv2.imread(image_path, cv2.IMREAD_COLOR)
img_gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
img = image.copy() #para no modificar la original
# Variables globales para la selección de puntos
global current_class, drawing, ix, iy, points_class1, points_class2
#matriz de markers inicia en cero
markers = np.zeros_like(img_gray, dtype=np.uint8)
drawing = False # Verdadero si el mouse está siendo presionado
ix, iy = -1, -1 # Coordenadas iniciales del punto
current_class = 1 # Clase actual
points_class1 = [] # Almacena puntos de la clase 1 - Objeto
points_class2 = [] # Almacena puntos de la clase 2 - Fondo
cv2.namedWindow("Seleccionar puntos")
cv2.setMouseCallback("Seleccionar puntos", select_points)
# selección de puntos
while True:
cv2.imshow("Seleccionar puntos", img)
key = cv2.waitKey(1) & 0xFF
if key == ord('1'): # '1' para clase 1
current_class = 1
print("Clase actual: 1 (Rojo)")
elif key == ord('2'): # presionar '2' para clase 2
current_class = 2
print("Clase actual: 2 (Azul)")
elif key == 27: # Presionar 'ESC' para salir
break
cv2.destroyAllWindows()
# crer markers a partir de los puntos seleccionados
for point in points_class1:
markers[point[1], point[0]] = 1 # markers objeto
for point in points_class2:
markers[point[1], point[0]] = 2 # markers fondo
# segmentar usando random_walker
labels_markers = random_walker(img_gray, markers, beta=beta, mode=mode)
# Crear la máscara de segmentación
mask = (labels_markers == 1) #donde esta el objeto
# aplicar la máscara
segmented_image = np.zeros_like(image)
segmented_image[mask] = image[mask]
# Guardar
os.makedirs(output_dir, exist_ok=True)
base_filename = os.path.splitext(os.path.basename(image_path))[0]
mask_path = os.path.join(output_dir, f'mask_{base_filename}.png')
segmented_image_path = os.path.join(output_dir, f'seg_{base_filename}.png')
cv2.imwrite(mask_path, (mask * 255).astype(np.uint8))
cv2.imwrite(segmented_image_path, segmented_image)
print(f'Máscara guardada en: {mask_path}')
print(f'Imagen segmentada guardada en: {segmented_image_path}')
Se definen las funciones calc_indice_jaccard y calc_indice_dice para determinar los índices correspondientes. Para determinar el Error de Rand Adaptado se utiliza adapted_rand_error de skimage.metricsFigura 2. Finalmente se define la función calcular_indices para calcular y sistematizar los índices en un data frame. Posteriormente se obtienen visualizaciones adecuadas.
# Función para calcular el índice de Jaccard a partir de dos imágenes binarias
def calc_indice_jaccard(img1, img2):
# Asegurarse de que las imágenes sean binarias
img1 = img1 > 0
img2 = img2 > 0
# Calcular la intersección y la unión
intersec = np.logical_and(img1, img2).sum()
union = np.logical_or(img1, img2).sum()
# Calcular el índice de Jaccard
indice_jaccard = intersec / union
dist_jaccard = 1 - indice_jaccard
return indice_jaccard, dist_jaccard
# Función para calcular el índice de Dice a partir de dos imágenes binarias
def calc_indice_dice(img1, img2):
# Asegurarse de que las imágenes sean binarias
img1 = img1 > 0
img2 = img2 > 0
intersec = np.logical_and(img1, img2).sum()
size1 = np.sum(img1)
size2 = np.sum(img2)
dice = (2. * intersec) / (size1 + size2)
return dice
# Función para calcular los índices y guardar resultados
def calcular_indices(base_dir, seg_grabcut_dir, seg_random_walker_dir):
resultados = []
# máscaras de referencia
ref_files = [f for f in os.listdir(base_dir) if f.startswith('mask_base_') and f.endswith(('.jpg', '.png'))]
for ref_file in ref_files:
base_filename = os.path.splitext(ref_file)[0] # Obtener nombre base sin extensión para manejar png o jpg
ref_path = os.path.join(base_dir, ref_file)
ref_img = cv2.imread(ref_path, cv2.IMREAD_GRAYSCALE)
# segmentación GrabCut
grabcut_file_base = os.path.join(seg_grabcut_dir, base_filename.replace('mask_base_', 'mask_'))
seg_grabcut_img = load_image(grabcut_file_base)
if seg_grabcut_img is None:
print(f"No se pudo cargar {grabcut_file_base}.png o {grabcut_file_base}.jpg")
continue
# segmentación Random Walker
random_walker_file_base = os.path.join(seg_random_walker_dir, base_filename.replace('mask_base_', 'mask_'))
seg_random_walker_img = load_image(random_walker_file_base)
if seg_random_walker_img is None:
print(f"No se pudo cargar {random_walker_file_base}.png o {random_walker_file_base}.jpg")
continue
# Calcular índices para GrabCut (gc)
jaccard_gc, dist_jaccard_gc = calc_indice_jaccard(ref_img, seg_grabcut_img)
dice_gc = calc_indice_dice(ref_img, seg_grabcut_img)
error_gc, precision_gc, recall_gc = adapted_rand_error(ref_img, seg_grabcut_img)
splits_gc, merges_gc = variation_of_information(ref_img, seg_grabcut_img)
# Calcular índices para Random Walker (rw)
jaccard_rw, dist_jaccard_rw = calc_indice_jaccard(ref_img, seg_random_walker_img)
dice_rw = calc_indice_dice(ref_img, seg_random_walker_img)
error_rw, precision_rw, recall_rw = adapted_rand_error(ref_img, seg_random_walker_img)
splits_rw, merges_rw = variation_of_information(ref_img, seg_random_walker_img)
# Almacenar resultados
resultados.append({
'archivo': ref_file,
'jaccard_gc': jaccard_gc,
'dist_jaccard_gc': dist_jaccard_gc,
'dice_gc': dice_gc,
'error_gc': error_gc,
'precision_gc': precision_gc,
'recall_gc': recall_gc,
'splits_gc': splits_gc,
'merges_gc': merges_gc,
'jaccard_rw': jaccard_rw,
'dist_jaccard_rw': dist_jaccard_rw,
'dice_rw': dice_rw,
'error_rw': error_rw,
'precision_rw': precision_rw,
'recall_rw': recall_rw,
'splits_rw': splits_rw,
'merges_rw': merges_rw
})
# Guardar resultados en un DataFrame y luego a un CSV
df_resultados = pd.DataFrame(resultados)
return df_resultados
Referencias
-
Un campo aleatorio de Markov (abreviado MRF por sus siglas en inglés) es un conjunto de variables aleatorias que poseen la propiedad de Markov descrito por un grafo no dirigido, lo que significa que la distribución de probabilidad del valor futuro de una variable aleatoria depende únicamente de su valor presente, siendo independiente de la historia de dicha variable. ↩
-
El algoritmo rápido de min-cut/max-flow es un método eficiente para resolver problemas de flujo en redes de grafos. Utiliza técnicas avanzadas de optimización para encontrar el flujo máximo que se puede enviar a través de una red desde una fuente hasta un sumidero. Una vez encontrado el flujo máximo, el algoritmo identifica el corte mínimo, que es el conjunto de aristas cuyo corte desconecta la fuente del sumidero con el menor costo posible. ↩
-
El Modelo de Mezcla Gaussiana (GMM, por sus siglas en inglés) es un modelo estadístico que asume que los datos observados son generados por una combinación de varias distribuciones gaussianas (normal) con parámetros desconocidos. ↩
-
Definido en https://www.frontiersin.org/journals/neuroanatomy/articles/10.3389/fnana.2015.00142/full ↩
-
Jia He, Chang-Su Kim, and C-C Jay Kuo. Interactive segmentation techniques: algorithms and performance evaluation. Springer, 2014. ↩↩↩↩↩
-
Carsten Rother, Vladimir Kolmogorov, and Andrew Blake. “grabcut” interactive foreground extraction using iterated graph cuts. ACM transactions on graphics (TOG), 23(3):309–314, 2004. ↩
-
Leo Grady. Random walks for image segmentation. IEEE transactions on pattern analysis and machine intelligence, 28(11):1768–1783, 2006. ↩